In my previous post, I explained how issuers, holders, and verifiers of verifiable credentials (VCs) work together to unlock new business value with self-sovereign identity (SSI). I also contrasted verifiable credentials with other digital credential approaches.
Now I’d like to go a bit deeper. Within the ocean of verifiable credentials, what variety exists? What motivates this variety? What should you know about different approaches to verifiable credentials as you fish for the right approach to adoption?

Photo credit: Papahānaumokuākea Marine National Monument, Flickr. (Public Domain)
The dimensions of digital verifiable credentials
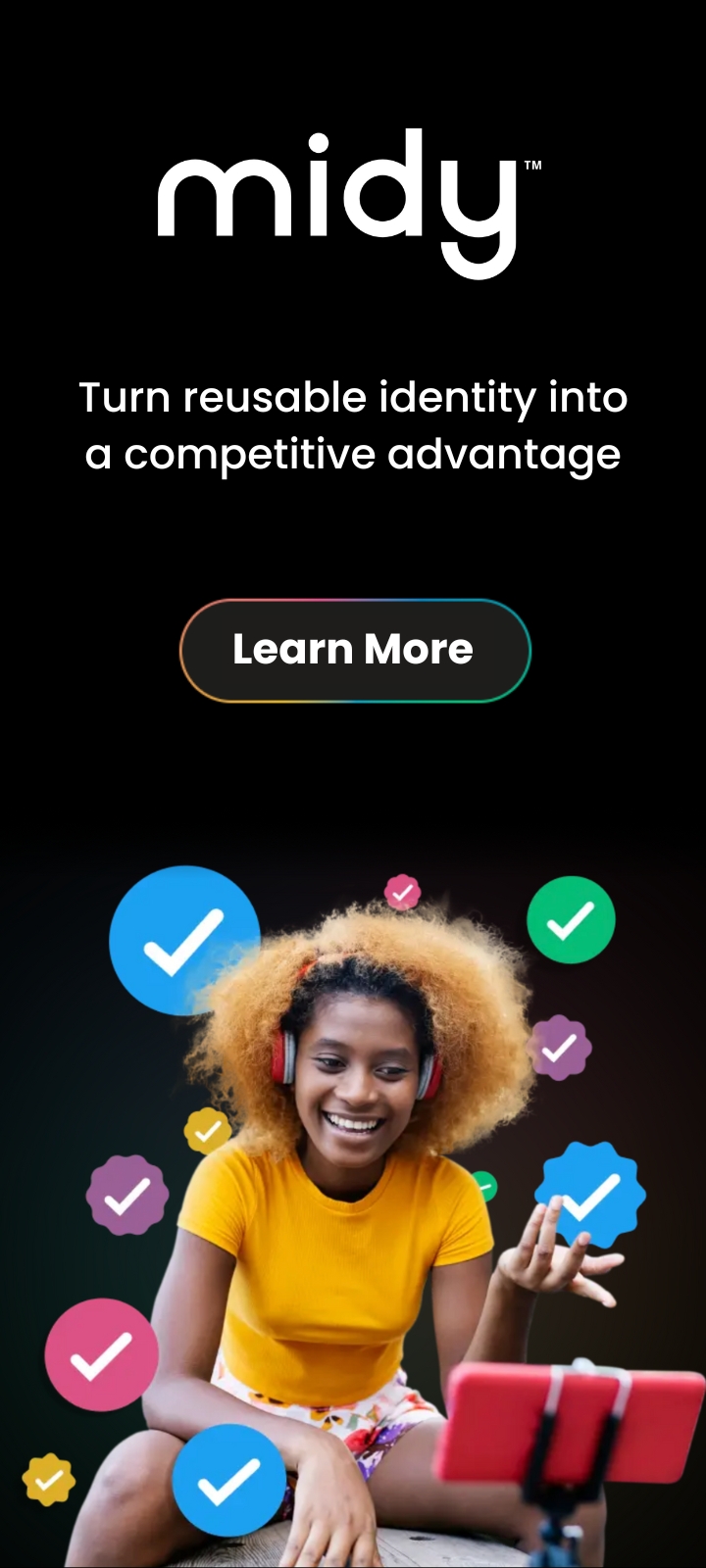
1. Schema
The most obvious way that VCs differ is in their data. A VC that represents a driver’s license and a VC that represents a credit card will have different types of data, even if they both describe the same person. Furthermore, two credit card credentials could differ in how they represent the same data for the same person–one putting the holder’s last name in a field named “last_name”, and the other in a field named “Surname.” And even if two credentials with the same data agree that the date of birth for the holder belongs in a field named “birthDate,” there is still a possibility of diverging on how the date in that field is encoded.
This is the schema dimension of credential variety. Schemas for credentials are proliferating, and this is not optimal. It’s desirable to draw schemas from a standard inventory, rather than having each issuer invent their own, because a credential with an unfamiliar schema is unlikely to be useful to verifiers. Business value flows in direct proportion to how broadly shared the community’s expectations are with respect to structure and content.
A promising effort to incorporate existing schemas (such as those found on schema.org) into verifiable credentials is underway. A description of this work can be found in Hyperledger Aries RFC 0250. There is also an effort to publish new schemas in a standard way; see Hyperledger Aries RFC 0281.
2. Rendering
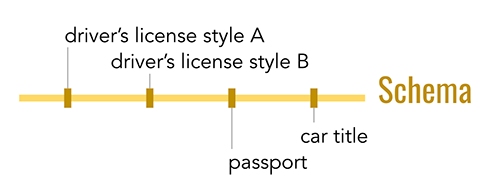
A less obvious source of difference in VCs is the convention used to render them into bytes in a file or message. The official VC standard specifies how a VC must be modeled semantically–but it doesn’t say what a VC data file has to look like on disk. In this rendering dimension, a choice could be made to represent the data model using XML, standard or custom binary formats, JSON, or similar.
Today, three rendering formats for VCs have meaningful momentum. All are JSON-oriented, but they differ in the details:
- The anoncreds format implemented in Hyperledger Indy and advocated by the Sovrin Foundation. This is the simplest format of the three, and the one that its proponents are least passionate about. It has a mature SDK with support in many languages, and has implementations in production. However, it is associated with a strong stance on privacy that only some organizations support (see below); this makes it somewhat controversial for reasons unrelated to the format’s technicalities. Its community began the work on standardizing rich schema that is linked above.
- A format based on JSON Web Tokens (JWTs) that is the basis of experiments by some in the Decentralized Identity Foundation community. JWTs are familiar from the problem domain of OAuth and identity providers. Numerous implementations exist. The theory here was that by building credentials atop JWTs, coding for developers and corresponding adoption would both be streamlined. However, JWTs limit semantic expressiveness and privacy features in certain ways; it’s not clear whether these limits are problematic.
- A format based on JSON-LD that has its roots in the semantic web. This format requires formal parsing by a library that is aware of namespacing and resolution semantics; it comes with a lot of expressive power but is somewhat dense and heavy. Library support is primarily focused on JavaScript.
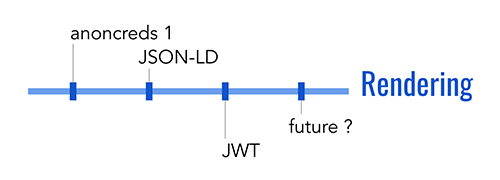
It is likely that the variety in these formats will collapse over time, either through convergence, attrition, or cross-format support. Today, however, this dimension represents a fork in the road as far as adoption is concerned; no existing libraries support all three formats. The closest to a safe bet is the Hyperledger Aries stack, which is building pluggable credential type handlers. This would allow multiple renderings to be supported in a single library or process.
3. Perspective of the holder
Verifiable credentials do not always describe the credential holder. For example, I could hold a credential that describes the pedigree of a race horse I own; that would make me the holder, but the race horse would be the subject.
More complex scenarios can arise, too. Consider a typical birth certificate: the primary subject of the credential is the child, but the certificate also makes assertions about the name and possibly other attributes of the mother, the father, the attending doctor, and maybe even the hospital where birth occurred. Each entity described by assertions in a verifiable credential is a subject, and the holder may be one or none of these subjects.
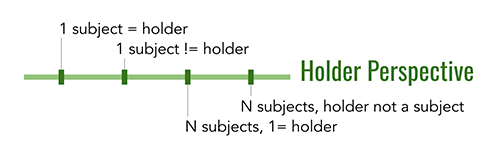
In the early days of verifiable credential adoption, use cases may focus entirely on credentials where 1 subject=holder. Besides being useful, such scenarios simplify questions of regulatory compliance and user experience in important ways. However, in the long run, credentials will need to support rich and varied positions on the holder perspective dimension.
4. Correlation
A fourth way that verifiable credentials differ is in their approach to personal privacy. When you share personal data through software, automatic mining and resharing of that data may become trivial. Correlating a person in many contexts is not a new risk, but the interconnectedness and perfect retention of big data engines may combine with verifiable credentials to make the situation worse. Seeing this problem, the verifiable credential community has had intense debates about where to make tradeoffs between privacy and complexity, and between technical versus legal protections. This results in two basic positions on a correlation dimension:
- Correlating credentials bind their holder to a revealed identifier that’s the same in every context; correlating through an identifier in this way imposes accountability by putting the holder’s reputation at risk. Such approaches take the position that it’s okay for every use of your credentials to identify you, because you’ll be correlated anyway, or because legal mechanisms will provide enough protection to keep you safe even if the data about you all connects. Today, the verifiable credential approaches that use JWTs and JSON-LD for their formats are correlating credentials.
- Non-correlating credentials help a holder to prove control over a credential in a way that is not identifying. These approaches take the position that you should be forced to opt in to correlation–the technology should never leak a correlatable identity without your explicit approval. The underlying cryptography required to achieve this goal is more demanding than ordinary digital signatures, which is why some wonder whether the tradeoff is worth the effort. Hyperledger Indy and Sovrin credentials embody this approach, with intellectual roots in ABC4Trust and Idemix.
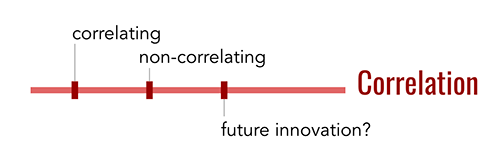
This philosophical debate is an important one, and I will explore it in greater detail in a future post.
It’s encouraging to note that there are ways these two positions might coalesce. Personal privacy is not as compelling when the holders of credentials are IoT devices, for example; this might present some opportunity for common ground. Likewise, both approaches have to deal with a problem that neither one addresses well yet, which is how a holder and verifier correctly deal with the privacy rights of a third-party credential subject. If a doctor holds a birth certificate that describes a child she delivered in the hospital, what protects the privacy of the child as the doctor uses that credential? Answering this question might trigger innovation in either or both approaches that makes this difference less divisive.
5. Payment
Credentials may intersect with payment in different ways. Some may be issued and used for free; others may be purchased; still others may incur a fee with every use. And while payment could be viewed as entirely independent from credentials, the binding is actually more interesting. This is because economics and levels of assurance are intertwined. For example, a top-secret security clearance may require thousands of dollars of field work and investigation, and bump its holder’s salary by even more. Thus, business models that allow economic value to be harvested in any and all credential interactions are a no-brainer.
With non-free credentials, who pays whom is interesting. The most straightforward model is probably holder-pays-issuer; we already expect to pay a fee when we apply for a passport. But other variations are equally possible, and they represent potential innovation that’s been somewhat impractical with physical credentials. For example, a holder that’s applying to a university might pay the university a fee to verify their academic credentials. A potential employer with stringent security requirements might pay an issuer to achieve assurance that an applicant has a government security clearance. A medical researcher might pay a holder for the privilege of verifying genetic information from credentials, as part of a study they’re conducting.
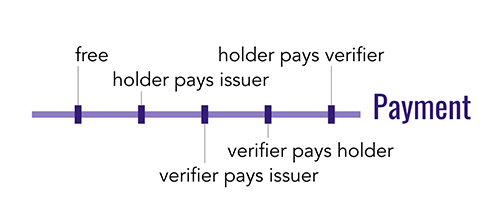
All of these scenarios represent different positions on a payment dimension of credential variety, and they have implications for the workflows that a credentialing technology must support.
Other dimensions
Credentials differ in other ways, too. For example, they may have different revocation profiles, they may be simple or complex, and they may be signed by a single entity or by a group. However, today you can choose an adoption strategy without worrying about these issues.
On the other hand, these five dimensions–schema, rendering, holder perspective, correlation, and payment–have important implications for any plan to adopt verifiable credentials. Different technology stacks have made different architectural choices about which possibilities they will promote, tolerate, or exclude. These choices limit interoperability and supportable use cases. If you’re considering the adoption of verifiable credentials, you should discuss all five dimensions with experts in the space.
In future posts, I’ll explore the driving considerations and the cost versus benefit of possible tradeoffs in these areas.
More in this series: