A rebuttal to Arnold and Longley’s article
Daniel Hardman, March 2020
|
CONTENTS
Rebuttal
|
Arnold and Longley write that ZKP-oriented credentials create irresponsible anonymity, letting malicious holders cheat. They are mistaken. Their article offers an unreasonable definition of ZKPs, and then draws fallacious conclusions from it. It quotes experts out of context, asserting anonymity standards for ZKPs that those experts don’t endorse. It posits foolish behavior from verifiers, and then imputes the consequences to ZKPs. It distorts the role of link secrets in a pragmatic security strategy. It dismisses biometrics and escrow techniques unfairly. It predicts proxy abuse without recognizing equivalent risk in ZKP alternatives, and without acknowledging that simple and effective countermeasures are available. It contains factual errors in its description of cryptographic commitments. All of this is explained in detail, with citations, in the rebuttal below.
The reality is that ZKP-oriented credentials are a powerful tool. They already deliver solid institutional and personal trust in production systems. However, like all tools, they can be misused. Expert cryptographers have been exploring that possibility for decades, and have described many safeguards; collectively, they have the potential to take trust to exciting new levels. A robust subset of protections is available today; more will be added as the ecosystem grows. In this maturing, ZKP-oriented credentials are similar to, not different from, their non-ZKP cousins.
Setting expectations
The Arnold Longley article enumerates worries that critics of ZKP-oriented credentials have surfaced less formally before. It is thus a welcome step; it makes concrete, public dialog possible. Readers can evaluate both sides of an argument on its merits.
Who are those readers? PhD cryptologists have been trading formal proofs about the integrity of ZKP-based trust for nearly three decades; neither the Arnold Longley article nor this rebuttal offers new insights for them. (Follow the academic trail in the Endnotes to verify this.) But the ideas may be new for the community that’s building verifiable credentials and self-sovereign identity. That is the audience for the special issue of IEEE Communications Standards where the article appeared, and for this rebuttal. It includes smart people from a variety of business, legal, government, and software backgrounds. Thus, it seems better to minimize the formalisms and terminology of specialists to keep this accessible for all.
Even so, analyzing something this complex demands thoughtful and sustained attention. I apologize in advance for the eye-glazing detail. I’ve organized this doc into sections, so you can skim or dive deep as desired. (Please note that to limit scope, this rebuttal focuses only on issues raised in the Arnold Longley article. The larger debate about credential models includes many additional topics. See Learning More for links.)
Arnold and Longley are critics of ZKP-oriented credentials, and have built an entire ecosystem around a competing technology. I am a ZKP proponent, and have built the opposite. Of course you should apply the same skeptical filter to both of us. Don’t forget to evaluate sources in the Arnold Longley article and here in my rebuttal (see Endnotes).
1. The article defines “zero-knowledge proofs” too narrowly, setting up a basic fallacy.
This is the first and most fundamental flaw in Arnold and Longley’s thinking. It taints nearly everything in the article, because there’s a huge delta between ZKP-oriented credentials as the authors imagine them, and ZKP-oriented credentials in production in the “real world.”
Arnold and Longley informally characterize zero-knowledge proofs like this:
ZKPs allow provers to prove they possess a certain piece of knowledge with the verifier learning nothing more than this fact.[AL, Introduction]
This definition — the only one they offer — does cover some of the correct semantic territory. However, it is too simplistic. Yet the authors insist on its narrowness, and its trivial application to credentials, in Example 2.5. This is where they want us to imagine proving that a single piece of information (over 18 status) is known to the holder. They suppose that this process will start with a single credential that attests exactly and only this one fact, and that the proving is not interactive. (See point 6 for a detailed critique of the example.)
Arnold and Longley cite nobody to justify their definition or its application to credentials. They can’t, because they haven’t faithfully described zero-knowledge proofs in general — and more importantly, they haven’t described ZKPs as used in credentialing ecosystems. Instead, the concept they’re working from is a subcategory of ZKP called a zero-knowledge proof of knowledge (ZKPOK)[1]. And they want to view ZKPOKs only as their most primitive variant: dealing with single facts in isolation, rather than the common case where ZKPOKs are composed into sophisticated systems that satisfy pragmatic trust requirements, using things like zkSNARK circuits, predicates, and thoughtful choices about context.
Commenting on the need to understand ZKPs as more than primitive thought experiments, one scholar states:
It must be noted that the concept of proof in ZKP is different from the traditional mathematical concept. Mathematical proofs are strict, using either self evident statements or statements obtained from proofs established beforehand. ZK proofs are more similar to the dynamic process used by humans to establish the truth of a statement throughout the exchange of information.[2]
Highlighting the possibility of interaction and common sense in ZKPs, another says:
Thus, a ‘proof’ in this context is not a fixed and static object, but rather an randomized and dynamic (i.e., interactive) process in which the verifier interacts with the prover. Intuitively, one may think of this interaction as consisting of ‘tricky’ questions asked by the verifier, to which the prover has to reply ‘convincingly’.”[3]
These comments align with the canonical definition of the broader and more relevant concept, from the seminal paper on ZKPs:
Zero-knowledge proofs are defined as those proofs that convey no additional knowledge other than the correctness of the proposition in question.[4]
This sets expectations appropriately about the intent, scope, and limits of ZKPs as used in ZKP-oriented credentialing systems. ZKPs are often mathematically rigorous — indeed, we want them to be, and formal definitions exist for many subvariants. However, the general category doesn’t let us ignore context and common sense. They aren’t limited to proofs of possession of a single fact. Their knowledge can be complex[5] (e.g., a proposition about the truth and relatedness of many assertions by an issuer about a subject). They need not demonstrate that the prover knows something.[6] Rather, the key characteristic of ZKPs in general is that they don’t leak “additional knowledge”:
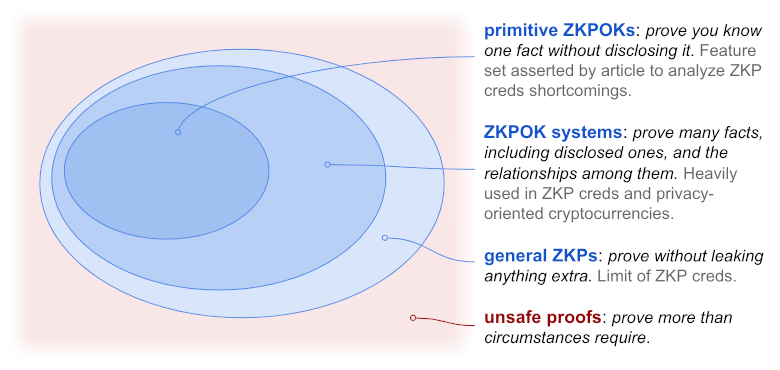
For a practical example of how ZKPOKs are built into complex systems in real-world ZKP credential usage, see point 6.1.
What would it take for a proof to fall outside the largest oval in the diagram above, failing to meet the zero-knowledge standard? It would have to leak knowledge beyond what circumstances require. In other words, it would have to be careless or promiscuous or clumsy. The ZKP standard — in the interests of privacy, be careful to never prove something beyond what’s required — is simply the familiar cybersecurity best practice to trust as little as possible (principle of least privilege).[7],[8] This cautious approach, advocated by NIST and the W3C’s Technical Architecture Group,[9] is the standard Arnold and Longley would have us believe is fatally flawed?
Large portions of Arnold and Longley’s reasoning is based on a composition fallacy that if something is true about a subcategory (simple mathematical ZKPOKs with obvious limits), it must be true about its parent category (complex ZKPs as embodied in rich credentials).[10] They would have us reason about a fictional mechanism that violates their narrow, imaginary standard of zero knowledge, rather than about production ZKP systems that meet pragmatic standards of zero knowledge, all day long every day. Most of the article’s section 2 falls apart due to this flaw.
1.1 The difference between these two definitions is substantial.
Here is how ZKP experts describe the capabilities of the systems they’re building:
Having acquired a credential, a user can prove to a verifier the possession of the credential. A proof of possession may involve several credentials acquired by the same user. In addition to the mere possession, a user can prove statements about the attribute values contained in the credentials using the proving protocol. Moreover, these proofs may be linked to a pseudonym of the user’s choice… [11]
But under the simplistic model imagined by Arnold and Longley, the common sense and flexibility of such a system disappears. They claim that all of the following features are illegal with ZKPs — even though they’re mainstream features in the tech they criticize:
- Prove the equality or inequality of two undisclosed values[12]
- Prove the relative ordering of two undisclosed values, or of one disclosed and one undisclosed value[13]
- Prove the relationship of an undisclosed value to a set, a merkle tree, or a hash pre-image[14]
- Disclose an actual value, and prove its relationship to values that are not disclosed.[15]
Note especially the last item in that list: You can disclose actual values in zero knowledge. If a verifier needs to know an identifier for the prover, there’s a ZKP for that. It may or may not be a primitive ZKPOK, but it’s still zero knowledge, as long as the value of the identifier is part of the legitimate scope of the proof, and that scope is never exceeded.
1.2 Evaluating whether “additional knowledge” leaks can only be done against situational requirements, not the article’s thought experiment.
The article asks us to evaluate zero knowledge by logical inference from an abstract definition. This is misdirection. Real evaluation decides what is necessary knowledge and what is additional, leaked knowledge by taking into account the requirements in a given situation:
- A perfect proof of exactly and only “over 21” is not zero-knowledge if the actual proposition that needed proving was “over 18” — no matter what technique is used and what its mathematical guarantees might be. This is because three extra years of precision are leaked about the age.
- A proof that discloses Alice’s genome and full medical history, her facts of birth, biometrics, everything from her passport, and the full history of all interactions she’s ever had with her government is zero-knowledge — if and only if the necessary facts are the ones proved, and if that proof did not go beyond what circumstances required.
1.3 Revealing an identifier can be (and is!) done in zero-knowledge.
Revealing something and claiming zero-knowledge might seem contradictory, but it’s not.
- Experts on ZKP-oriented credentials have noted that they “may involve direct assertions of identity,”[16] that “these proofs may be linked to a pseudonym of the user’s choice,”[17] and that “Peggy should be able to reveal none, some, or all of her attributes during the showing protocol.”[18]
- The ABC4Trust system architecture includes an entire section, 2.5, about this possibility.[19]
- The Hyperledger Indy ecosystem has supported disclosure of identifiers since version 1.0.
- The company I work for, Evernym, has been demoing use cases that involve ZKP-based disclosure of identifiers of varying strengths (names, driver’s license numbers, etc) since Jan 2018.
- The world’s first production deployment of Verifiable Credentials, the Verifiable Organizations Network in British Columbia, issued Indy-based ZKP credentials with strong identifiers (e.g., a business’s government-issued ID) the day it went live in 2018, and has been doing so ever since. These credentials are regularly used to prove things about businesses, where the requests for proof include disclosure of those identifiers.
To understand how this could be a feature of ZKP-oriented credentials, consider a scenario where a particular context requires you to prove:
- The name on your passport
- That this value was signed by nation X
The zero-knowledge way to satisfy these requirements is to disclose the name (proving that it dovetails with the unrevealed remainder of the passport) — but to establish the nature of the signature without disclosing its actual value. Net effect = weak identification. The non-zero-knowledge way is to disclose the name plus a globally unique signature value. Net effect = strong identification. Both methods satisfy the proof criteria; the non-ZKP approach leaks something extra and lessens privacy as a result.
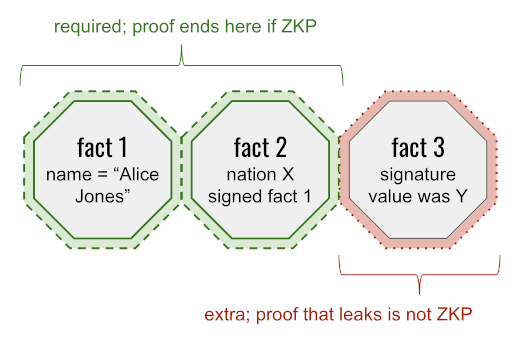
(By the way, non-ZKP-credentials would typically reveal much more than just a name and a signature in this scenario; the most common approach would be to reveal all the other fields in your passport, too. This is part of the larger discussion about why ZKP’s answer for selective disclosure is compelling — but since Arnold and Longley don’t argue it, I’ll just note it here. See Learning More to dive deeper.)
1.4 The bad definition undermines the analysis.
Numerous inaccuracies in the article stem from Arnold and Longley’s straw man. An exhaustive catalog isn’t worthwhile, but two important examples are:
However, because such a proof provides zero knowledge, it is repudiable — a key difference from the traditional digital signature approach. [Arnold and Longley, section 2.4]
And:
ZKP ABC systems aim to provide privacy to the user by exposing no additional information beyond what is strictly needed by the verifier. However, a user cannot prove in zero-knowledge that they possess a certain attribute. [Arnold and Longley, Conclusion]
If ZKP-oriented credentials were limited to primitive ZKPOKs, claims like these would be true. But they’re not. We’ve corrected the mistaken conception about disclosure in ZKPs (point 1.3); for more about repudiation, see point 5.
2. It exaggerates and quotes experts out of context to build a straw man model of anonymity.
A pivotal claim in the article is that ZKP-oriented credentials commit both parties in a proving interaction to the absolute anonymity of the prover.
As a contributor to ZKP-oriented credential technology, I reject this as exaggeration (see point 1.2 and point 1.3). The real goal of ZKP-oriented credentials is to allow reasonable private spaces. Outside the digital context, we use bedroom and bathroom doors to limit publicness. I claim these barriers are helpful (though they have little in common with “absolute anonymity”) and that ZKP-oriented credentials offer similar pragmatic benefits. Mastercard summarized this common-sense view of privacy well in 2019:
Digital identity confirms an individual’s right to access a particular service without disclosing unnecessary data. It does this by securely accessing from trusted sources only the minimum data required. Where the stakes are low, proving identity should be simple; like the face-to-face recognition that used to be good enough for your local bank manager or doctor. Digital identity applies that simplicity and recognition to the digital realm. Complex checks are reserved for interactions with higher stakes and more risks, such as proving eligibility for a mortgage or accessing medical records.[20]
But Arnold and Longley insist upon an ultra-exacting interpretation of ZKP goals. They quote ZKP experts (from a 148-page document, without citing a page number) to make the point:
As mentioned in the introduction, efforts are being made to use ZKPs to limit the amount of additional correlatable information the user shares with the verifier. The idea is for a user to prove they have access to a valid credential without revealing the issuer’s signature or the holder’s identifier. Such credential presentations are “cryptographically unlinkable and untraceable, meaning that verifiers cannot tell whether two presentation tokens were derived from the same or from different credentials, and that issuers cannot trace a presentation token back to the issuance of the underlying credentials.”[Arnold and Longley, section 2.4, expert subquote in blue]
The article then conflates “cryptographically unlinkable” proofs in the quote with general unlinkability of humans (another composition fallacy like the one discussed in point 1), and uses this to justify their claim of anonymity:
For the purpose of unlinkability, a presentation must not include any protocol information that could uniquely identify the user. In this way, ZKPs anonymize the holder of the credential, rendering their activity untraceable.[Arnold and Longley, section 2.4]
To reinforce the importance of this claimed categorical guarantee, Arnold and Longley repeat a subset of the quote a few paragraphs later:
Remember, “verifiers cannot tell whether two presentation tokens were derived from the same or from different credentials.”[Arnold and Longley, Example 2.5, expert subquote in blue]
Note where the quotation marks occur. Only blue text is from the experts; Arnold and Longley begin quoting halfway through a sentence, gluing their own framing of a concept to a description from the experts. So do they fairly represent the intent of the original? Here is the blue quote in its larger context (from page 17 of the ABC4Trust documentation):
Presentation tokens based on Privacy-ABCs are in principle cryptographically unlinkable and untraceable, meaning that Verifiers cannot tell whether two presentation tokens were derived from the same or from different credentials, and that Issuers cannot trace a presentation token back to the issuance of the underlying credentials. However, we will later discuss additional mechanisms that, with the User’s consent, enable a dedicated third party to recover this link again (see Section 2.5 for more details).
Obviously, presentation tokens are only as unlinkable as the information they intentionally reveal. For example, tokens that explicitly reveal a unique attribute (e.g., the User’s social security number) are fully linkable. Moreover, pseudonyms and inspection can be used to purposely create linkability across presentation tokens (e.g., to maintain state across sessions by the same User) and create traceability of presentation tokens (e.g., for accountability reasons in case of abuse). Finally, Privacy-ABCs have to be combined with anonymous communication channels (e.g., Tor onion routing) to avoid linkability in the “layers below”, e.g., by the IP addresses in the underlying communication channels or by the physical characteristics of the hardware device on which the tokens were generated.[21]
What the experts actually say is a lot more nuanced than what the AL article asserts: ZKP-oriented presentations are unlinkable “in principle … [h]owever…”. And there’s a lot of “however” to consider.
An important nuance that’s entirely suppressed by Arnold and Longley is the moderating effect of non-cryptographic factors like disclosed data, communication channels, history, and other protocols. The impact of such factors can be profound.[22][23],[24],[25] It is one reason why the zeroness in ZKPs must be evaluated in context (see point 1.2): non-cryptographic factors can also be evaluated only in context.
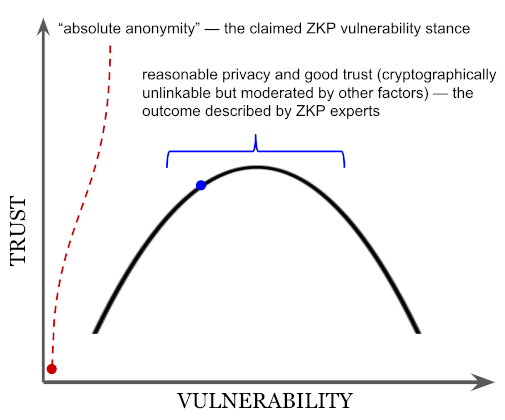
This simplistic view of anonymity is a big deal. Arnold and Longley’s whole argument rests on the assertion that a ZKP prover is perfectly anonymous (exaggeration), and that in this state they aren’t vulnerable in any way (exaggeration) because their reputation isn’t at risk (oversimplification). From there, they conclude that the sweet spot in the privacy vs. vulnerability tradeoff is a point where some privacy must be traded away in the cryptography. But the experts they misquote are careful to itemize some ways that absolute anonymity is only a theory anyway; according to these experts, practical factors move an interaction toward the middle of Arnold and Longley’s curve independent of cryptography. The AL article is arguing a straw man, making much of it irrelevant.
2.1 The difference between “real world” and theory is significant.
In a physical and human world, exploits aren’t as easy as they look on paper, vulnerability to other humans is rarely zero, and imperfect proof is often fine.
We can sometimes infer things from ZKP-based interactions, no matter how pure the ZKP itself is. Consider proving just your nationality in zero knowledge. Normally this would preserve a lot of privacy–but if you do it on the International Space Station, it could be uniquely identifying. Likewise, if I ask for a ZKP from a remote party and I get a response 10 milliseconds later, I can reasonably infer that the party I’m interacting with is located within 5 light milliseconds (1500 km) of my current location — light couldn’t have carried the interaction any faster. With somewhat less assurance, I can guess that the party is on my local network, since ping times are usually not that fast for parties many network hops distant.
ZKPs presented in person — Alice requesting access to a voting booth, for example — are an important use case that the article doesn’t consider at all. Such interactions carry significant amounts of context besides what’s embodied in mathematics. Regardless of ZKP anonymity, malicious Alice probably can’t vote twice with the same credential, if she appears before the same election official twice in quick succession.
What this means is that in “real world” usage, ZKP-oriented credentials target and deliver “pretty good” zero knowledge, not the anonymity that Arnold and Longley would have us believe. This “pretty good” zero knowledge combines with verifier requirements for “pretty good” assurance to allow reasonable behaviors that protect everyone.
For an example of mutual accommodation with “pretty good” assurance, consider tobacco regulations in the United States. These regulations make it illegal to sell tobacco products to anyone under age 21. However, the regulation settles for fuzzy enforcement — vendors are supposed to demand photo ID from anyone who appears to be younger than 27.[26] Judging “under 27” is left to the vendor, and auditing is unpredictable. The vendor and the person buying tobacco are mutually vulnerable to one another in a dynamic way; each balances risk versus benefit when deciding whether to strengthen proof. Undoubtedly some fraud occurs, but a significant deterrent effect is also created.[27] Because ZKP-oriented credentials allow granular escalation of proof, they are a natural fit for this sort of situation, even though the guarantees of the interaction don’t match a mathematical ideal.
3. It oversimplifies the basis of trust.
Arnold and Longley assert a general principle that they call the Trust Paradox: “No trust without vulnerability.”[section 2.1] They elaborate two key examples of this paradox in action, across sections 2.1, 2.2, and 2.5:
- An issuer can be trusted if they risk their reputation as an honest credential signer.
- A prover can be trusted if they degrade privacy enough to risk their reputation as an honest credential holder.
This is fine, as far as it goes — but the thinking is too narrow. Trust in others arises out of confidence in constraints; reputation risk is only one of many constraints on human behavior.
- The public trusts people who operate Bitcoin miners because their machines are constrained by an ungameable proof-of-work algorithm — not because of reputation risk.
- A bank trusts employees not to steal cash from the vault after hours because the vault has a time lock that can’t be overridden — not because of reputation risk.
- A detective trusts a suspect’s innocence because fingerprints don’t match — not because of reputation risk.
- Acme Corp trusts a newly hired salesman to work hard because he’s paid on commission — not because of reputation risk.
- A mom trusts her son not to put his hand in a candle’s open flame because it will hurt — not because of reputation risk.
- Kidnappers trust family members to pay a ransom because the victim is dear — not because of reputation risk.
A better formulation of the Trust Paradox would be: “No trust without constraints.” (And that is not a paradox at all; it’s the same common sense that tells us we better strap in on a roller coaster.) Despite Arnold and Longley’s claims, ZKP-oriented credentials let prover reputation be risked in interactions, if circumstances make that constraint desirable. ZKP credentials also offer many other options for constraining the prover to achieve trust. See point 1.3, point 4.1, point 4.2, and point 4.3; also, Learning More.
4. It mischaracterizes link secrets.
The target of much of Arnold and Longley’s critique is a mechanism that binds ZKP-oriented credentials to their holder. The article calls this mechanism correlation secrets in some places, and link secrets in others. These are synonyms; we’ll use the shorter term.
Link secrets are large random numbers that only a holder is supposed to know. Specifically, they should be withheld from the issuer and the verifier; the need to keep them secret from others in the ecosystem can be exaggerated.[28] The math behind them is a bit esoteric, and it trips up Arnold and Longley (see point 8). A simple though imperfect[29] analogy is to think of them like a tool that’s used to generate watermarks. A holder and issuer cooperatively use link secrets to “watermark” credentials at issuance time, to bind them uniquely to the holder. Later, during a proving interaction, the prover shows the verifier in zero knowledge that they can generate a “watermark” that shares carefully selected characteristics with the original. This is not possible unless the prover knows the holder’s secret; thus, it is evidence that the credentials used for proving belong to them instead of someone else.[30]

{kind=link}
Arnold and Longley are correct to claim that the guarantees associated with link secrets come with caveats. So do watermarks, of course. But neither link secrets nor watermarks are useless; they are both components of a larger strategy to eliminate fraud. The article distorts this:
| Article claim | Fact |
|---|---|
| Link secrets are the only mechanism that ZKP-oriented credentials use to prevent fraudulent transfer. | Plenty of mechanisms[31] exist to bind ZKP-oriented credentials to their legitimate holder. This includes the same choices available with non-ZKP-oriented credentials: disclosure of identifiers or other data fields to make reputation vulnerable (see point 1.3). It also includes biometrics (see point 4.1 below) and other techniques that the Arnold Longley article doesn’t mention (e.g., agent authorization policy).[32] Each mechanism has tradeoffs. Link secrets are just another option, with another set of tradeoffs. ZKP creds generally contain a commitment to them, and ZKPs generally prove against them, but verifiers who don’t want them can base trust on something else on a case-by-case basis, per their fancy. Link secrets can also be combined with other options; they are not mutually exclusive. |
| Provers are forced to accept link secret guarantees if they interact with a prover that uses ZKPs. | Nobody forces a merchant to accept currency as legitimate using just a watermark as evidence; merchants can set whatever standard for themselves they like. Similarly, verifiers — not the tech they use — decide what level of assurance will satisfy them (see point 6.2). If they want assurances beyond link secrets, they are perfectly able to demand them — and provers can provide such assurances inside the ZKP-oriented credential ecosystem. |
| It’s easy to share link secrets, and hard to detect that they’ve been shared. | It is true that the mechanics of sharing secrets (of any kind) are easy, but incentives can drastically alter whether link secret transfer is likely (see point 4.2). Fraudulent reuse of these secrets is detectable at the option of the verifier (point 4.3). |
4.1 Biometrics can prevent fraud without destroying privacy.
Biometrics have long been recommended by the Electronic Identity Credential Trust Elevation Framework from Oasis, based on numerous specs and standards from NIST.[33] Yet the article dismisses biometrics in two sentences, claiming that they “cut against data minimization goals.”[section 3.1]. Arnold and Longley apparently believe that using biometrics must necessarily expose strong correlators to the verifier, and also that revealing strong correlators is by definition disallowed by ZKPs. Notice that they don’t cite anybody or provide any reasoning to justify these assumptions.
The same issue of IEEE Communications Standards magazine that published the Arnold Longley article includes an in-depth exploration of how biometrics can be combined cleverly with zero-knowledge proofs to achieve data minimization goals. [34] It describes three usage patterns:
| Biometric Pattern | Trust characteristics |
|---|---|
| Pocket Pattern | Holder carries biometric template inside credential, and reveals it to verifier along with a fresh scan. Verifier evaluates match. |
| BSP Pattern | Holder carries biometric template inside credential, and reveals it to biometric service provider (BSP) along with a fresh scan. BSP attests match to verifier. |
| Low-fi Layers Pattern | Holder carries many low-fidelity biometric templates that each preserve herd privacy because of their imprecision. Multiple matches against low-fidelity templates can be layered to achieve exactly the privacy vs. trust tradeoff that circumstances demand, without the strong identification of ultra-high fidelity matches. |
Even the Pocket Pattern, which has the least privacy of the three, achieves some data minimization by eliminating the need for issuers to build a database of biometrics as they issue. The BSP Pattern and the Low-fi Layers Pattern go beyond this, minimizing how much biometric data the verifier sees as well.
Although Arnold and Longley don’t explain, they would likely discount the sort of interaction in the BSP pattern as introducing another trusted party; that is the basis of their critique of ABC4Trust’s inspectors:
We agree with ABC4Trust’s conclusion that the solution to the privacy-trust problem is an additional trusted party. But, if knowledge of the user’s identity and activity is ultimately necessary for maintaining their vulnerability, ZKPs should not be used to remove this knowledge in the first place.[section 3.5]
But if that’s their argument, note the false equivalence: the BSP pattern trusts different parties for different things. The BSP knows a biometric match is needed, but has no idea what credentials are involved, what else is being proved, or who the prover purports to be. The verifier knows that a biometric match is asserted by the BSP, but not what the biometric data in the credential or the biometric data from the most recent scan looks like. That is the cybersecurity principle of diffuse trust in action.[35] In contrast, the inspector model that Arnold and Longley criticize, and the trusted model they advocate, both show a third party exactly what the verifier would see if privacy were totally ignored. That is simple proxying. The trust and privacy implications are quite different.
4.2 Escrow can drastically change incentives for fraud.
The owner of a link secret, Alice, can put either money or PII into escrow, such that the value can be confiscated if Alice abuses trust. This changes incentives for a malicious Alice.
For example, suppose Alice joins an online forum and wants to operate anonymously. The forum has a no-trolling, no-bullying policy. Alice uses verifiable encryption to encrypt her name and phone number (step 1 below), gives the encrypted payload to the forum (step 2a), and submits the key to decrypt this PII to the forum’s independent escrow service (step 2b). Verifiable encryption means Alice can prove to the forum that she’s encrypted her real PII, and that she’s truly escrowed a key to unlock it.[36] Alice can now operate anonymously (step 3) — but if the forum ever finds her guilty of abuse, it can approach the escrow service with proof of the abuse and get Alice’s key so she can be de-anonymized (step 4). This is vulnerability, but it’s conditional. And the condition is one that honorable provers can accept with little risk.
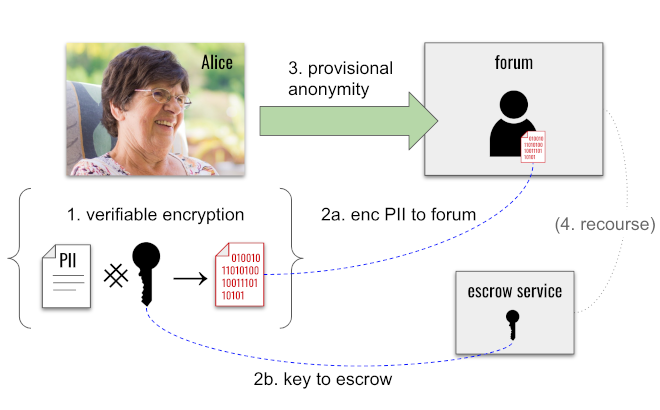
Arnold and Longley point out [section 3.4] that verifiers and provers both have to agree before such mechanisms become an option. This is true, and it should temper our enthusiasm to some degree. However, the article then dismisses the idea outright by claiming that escrow requires the verifier and prover to trust someone extra, and that this defeats the whole purpose of ZKPs. This is a distortion; it doesn’t do justice to thoughtful work on this problem that’s existed at least since early ZKP-oriented credential systems were described, along with escrow-based transfer protections, in 2001.[37]
As a narrow technical point, it is true that something new — the escrow mechanism — must be trusted in some way to use this approach. However, as with the discussion about biometric service providers (point 4.1), equating the trust that must be placed in an escrow mechanism with the trust that must exist between verifier and prover is a mistake. The escrow mechanism doesn’t need the least understanding of verifiable credentials or link secrets. It doesn’t need to know that proving is taking place, or when it happens, or who’s involved, or what’s at stake, or any other context. It just needs to reliably release escrowed material according to pre-established rules. Furthermore, its conformance to those rules can be publicly audited without undermining Alice’s privacy at all. This is not much different than trusting a phone to emit packets according to TCP/IP rules as we send an encrypted message; the mechanics of sending and the dynamics of trust established by the encryption are not really part of the same trust equation.
If any member of the public can approach the escrow service (e.g., “Alice abused trust by sharing her link secret, and I can prove it, because here it is.”), and if the escrow service is willing to attest in zero knowledge to whether a particular escrow relationship is still active, then many of Arnold and Longley’s other abuse scenarios are unlikely. The minute Alice abuses trust, she loses the secret as well as whatever value she escrowed as a bond — and the whole world can know it. Notice that the specific abuse of sharing link secrets disappears without proactive policing; the bond gives malicious parties an incentive to become the proactive enforcement without other parties lifting a finger.
Escrow is not a perfect tool. Alice could share her link secret with her sister, who could be dishonest with respect to the world but totally trustworthy toward Alice. However, escrow does alter the analysis of link secret reuse substantially. And the corner cases that it doesn’t alter apply to non-ZKP-oriented credentials as well, as we’ll see in point 9.
4.3 Link secret reuse is detectable.
Under carefully structured ZKP conditions, a verifier can tell whether a link secret has already been used to prove something in a given context. This detection technique — a small change to mathematical inputs — enables scenarios like “one person, one vote” or “one ticket, one admittance” while still giving the option of reasonable anonymity for holders of ZKP-oriented credentials. The prover knows when challenged for proof that the verifier is using this technique, and can therefore refuse to cooperate; the verifier can detect whether the prover is cooperating. This gives each party the chance to opt out of a completed interaction.
The mathematics of this detection technique have been publicly described[38] and will not be repeated here. Arnold and Longley “do not contest the mathematics of these schemes” [Introduction], presumably including this specific application of them.
What Arnold and Longley do dispute, however, is the wisdom of using this technique, based on two concerns:
- They claim that this form of reuse encourages correlation:
In the traditional case, users typically keep their different identities, or collections of attributes, separate from one another. Cross-identity information is never intended to be shared in clear or even encrypted form. Although this may inhibit the user’s ability to mix and match credentials across identities, it is the cost of keeping their identity linkage secret at all times. ZKP ABC systems that encourage users to mix all of their identities and attributes together introduce a new risk: correlation across identities.[section 3.3]
- They assert that the link secret is given to the verifier in encrypted form; if crypto advances allow later decryption, this is a security and privacy risk.[section 3.3]
Claim 1 is full of problems. It begins with the falsehood that “in the traditional case, users typically keep their different identities, or collections of attributes, separate from one another.” In practice, just the opposite is true: holders of all credential types (ZKP-oriented or not) tend to coalesce all their identities in internal views, because to the holder, all these attributes actually describe their singular, coherent identity. We want this to be true; Alice shouldn’t ignore how much she owes to lender 1 when she considers borrowing from lender 2, and she shouldn’t ignore that she’s a citizen of New Zealand when she applies for a passport from Italy. Alice the borrower and Alice the citizen and Alice the employee are mere projections of a unified whole, manifested externally per circumstances.
This is why users want one wallet to hold all of their credentials, not many. It’s why they need help with hundreds of separate logins on the internet — the very reason why password managers exist as a product category. And it’s why ZKP-oriented credentials use a link secret: to model in tech what already exists in the minds of the users, so software can manage it safely and intelligently on the user’s behalf. ZKP-oriented credentials automatically generate unique projections of that identity in every interaction, precisely so things can look separate to an outside observer without the user having to worry about keeping all this stuff separate on the inside.
Introducing a technique to detect reuse of a link secret doesn’t change incentives; it just shifts, very slightly, who can correlate. Normally the only person who sees the correlation is the holder, Alice; when the reuse detection feature is used, the verifier becomes capable of an anemic form of correlation that prevents fraud, but it still can’t identify her. This is not a risk of “correlation across identities” for an honest Alice, but it is an incentive not to attempt the fraudulent correlation of unrelated identities, for a malicious Alice.
The falsehood of claim 1’s verbiage that “Cross-identity information is never intended to be shared in clear or even in encrypted form” has already been discussed (see point 1.3).
Claim 1 is also wrong to assert that traditional ZKP use “may inhibit the user’s ability to mix and match credentials across identities.” Every alternative to link secrets, including all non-ZKP-oriented credential systems, creates significant obstacles to mixing and matching credentials across identities; only ZKP-oriented credentials offer an elegant, workable solution. Without them, users must either acquire huge numbers of “atomic credentials” that represent the exact permutations of attributes they want to share, or deal in elaborate merkle trees of signatures for each credential, or pay for and manage huge numbers of public DIDs, or leak unnecessary PII constantly. With them, users can have one driver’s license, one passport, one birth certificate, and no public DIDs — and generate endless unique combinations of attributes on the fly, exactly suited to circumstances, while paying almost no attention to the underlying technicalities.
So if claim 1 isn’t a reasonable concern, what about claim 2? It arises from a misunderstanding of the underlying cryptography, as discussed in detail in point 8.
The bottom line here is that it’s easy, safe, and sometimes appropriate to detect link secret reuse. The technique is not mandatory, but it does give verifiers useful options. And this reinforces the larger point, which is that link secrets are a useful tool, if they’re used wisely instead of naively as the article wants us to imagine. They can be combined with techniques like this one, or like escrow, or like biometrics, or like non-ZKP-like identifier disclosure, to achieve whatever level of assurance a verifier wants.
5. It misses nuances of repudiation.
Arnold and Longley imagine repudiation as a single quality. But when Alice proves something to Sofia in private using a credential, two separate repudiation-and-reputation questions actually arise:
- Can Alice later repudiate to Sofia the fact that she shared the credential, or what the credential contained?
- Can Alice later repudiate to the public the fact she shared the credential with Sofia, or what the credential contained?
All credential technologies I know, including the ones oriented around ZKPs, enforce that the answer to Question 1 must be “No”. Alice can’t deny to Sofia what happened in private with Sofia.
Question 2 is far more interesting. Arnold and Longley assert that the answer to this question, too, must be “No”. Or more precisely, they don’t recognize the distinction between these two questions, and the only answer they accept for the conflated combination is “No.” If that’s your position, then anything Alice proves to Sofia in confidence can later be revealed–by Sofia, by government subpoena, by a hacker, by a malicious sysadmin–and proved, publicly or to third parties. Alice gives away, forever, her control over proving whatever facts she shares with Sofia.

Sometimes, this is exactly what we want. If the proved fact is that Alice agreed to pay SofiaBank for a mortgage, then SofiaBank must be able to prove it in a court of law, regardless of Alice’s cooperation.
But what if Sofia is a medical researcher, and Alice is proving that she’s HIV positive? Should Sofia be able prove Alice’s HIV status to the public, just because Alice proved it to Sofia — or might we sometimes want this to require independent consent? What if Sofia works in a company’s HR department, and Alice is proving her identity to Sofia so she can file a sexual harrassment complaint against her boss? Should Sofia be able to prove Alice’s identity to the boss, just because Alice proved it to her?
Note that these same questions can also be framed in terms of a verifier’s best interests. Would the medical researcher like the option of knowing Alice’s HIV status, without having to insure against the risk that a hack will leak proof of HIV status to the public? Would Sofia in the HR department like to know for sure who Alice is, without worrying that a malicious sysadmin can “out” the victim?
ZKP-oriented credentials are nuanced and give the prover and verifier options; non-ZKP-oriented credentials are a blunt instrument:
| Question | ZKP answer | non-ZKP answer |
|---|---|---|
| Can Alice repudiate to Sofia? | No (enforced by crypto) | No (enforced by crypto) |
| Can Alice repudiate to others? | Maybe (verifier and prover agree in advance to terms of use; enforced by crypto) |
ZKP-oriented credentials are fully capable of supporting public non-repudiation, like their simpler counterpart. If the verifier and prover agree that a proof will be non-repudiable (e.g., in the case of the mortgage), then the proof makes non-repudiation enforceable through the cryptography. This is, and always has been, the default behavior of the ZKP-oriented credentials in Hyperledger Indy. However, if the verifier and prover both agree that a proof should be repudiable to parties outside the private interaction (e.g., in the case of the HIV test), then the zero-knowledge proof can commit Alice only to Sofia; it’s none of the public’s business. No comparable option is available without zero-knowledge proofs. Therefore, ZKP-oriented credentials are more powerful with respect to repudiation than the alternative, not the opposite.
Arnold and Longley appear not to understand this — perhaps because they assume (wrongly) that the only way to achieve non-repudiation is to disclose a signature value (see point 1.3). Thus, many of the article’s proximate and downstream arguments about repudiation fall apart.
6. The trust gaps it highlights arise from foolish and unlikely assumptions, not ZKP properties.
Arnold and Longley build their case against ZKP-oriented credentials by imagining the need for evidence of “over 18” status [Introduction]. This is a common example used in ZKP literature, and it’s fine as a starting point. But Arnold and Longley distort it by positing that a ZKP-oriented approach to this problem should begin with a credential containing exactly and only that assertion. This takes them far from reality; ZKP proponents would never agree to such a credential as a reasonable beginning. Why?
- Because the posited credential contains no issuance date or expiration date, the “over 18” status cannot be evaluated with respect to time — past, present, or future. No verifier requires “over 18” without some reference to time; therefore the posited credential is useless even before we begin analyzing what proofs might be generated from it.
- Because the credential lacks any revocation feature, we can’t evaluate whether its original issuer stands behind what they once asserted.
- Such a starting point conflates the distinction between a credential and a proof. All proofs are not credentials, any more than all mammals are cats. What the verifier requires is proof of “over 18” — NOT whatever scraps of information can be gleaned from a credential of “over 18.” A major purpose of ZKP-oriented credentials is to enable this distinction, so you prove “over 18” using whatever common, rich credentials are handy, like a driver’s license or a passport. Such credentials are not “intended to communicate to the verifier Alice is over the age of 18” as Arnold and Longley want us to believe [Example 2.5] — they’re intended to prove general facts that the holder can adapt to whatever proving requirements arise. They typically have dozens of useful fields, including birthdates instead of a boolean “over 18” assertion.
Starting from a degenerate, flawed credential that doesn’t resemble any likely reality, Arnold and Longley argue that the proofs possible with their imagined credential have “trust gaps.” Of course a credential with inadequate evidence will produce inadequate proof; this is a “begging the question” fallacy.
6.1 An example with more realistic assumptions
A realistic scenario should actually look like more like what follows, assuming the behavior of a robust ZKP-oriented credential technology like the one in Hyperledger Indy. Given that Alice possesses a digital driver’s license, a verifier asks her to prove that:
- She possess a credential A,
- matching schema B (a canonical driver’s license schema),
- containing field C (birthdate),
- where C contains a date value more than 18 years before today’s date,
- and the credential is bound to Alice as holder with mechanism D so others can’t use it,
- and the credential has an revocation index, E, which Alice knows,
- in revocation registry F,
- and the credential’s status in F is unrevoked
- and Alice knows a signature G,
- from issuer H (the government authority that issues driver’s licenses),
- endorsing the unmodified value C in the context of A, B, D, E, and F.
(Notice how this builds a sophisticated knowledge system from individual primitive ZKPOKs, as described in point 1.)
Of course, the verifier need not track all these details in constructing a proof request, and Alice need not track them as she decides how to respond; technicalities can be (and typically are) handled by software. Both parties probably just understand the request as “prove with your unrevoked, valid driver’s license that you’re over age 18 today.” However, the list above is a good approximation of what code actually manages with such a request. The options for generating and evaluating proof are much richer than what Arnold and Longley want us to imagine.
6.2 Verifiers, not technology, create trust gaps.
So, what of the key conclusion of Arnold and Longley’s Example 2.5 — that ZKPs anonymize the holder/prover, effectively erasing the part of the proof labeled “D” in point 6.1 above?
To answer that question, consider who does the erasing that creates the imagined trust gap. Is it the verifier, or the prover? If it’s the verifier, then they’re foolish; they’ve voluntarily opened themselves up to fraud by not requiring the prover to be the legitmate holder of the credential. If it’s the prover, then the proof doesn’t match the requirements of the verifier. Only a foolish verifier would accept that. Either way, a “trust gap” only occurs with a foolish verifier. Nothing in the tech requires verifiers to be foolish. In fact, the tech goes out of its way to provide wise, safe defaults. Plus, exactly the same sort of mistakes can occur with foolish verifiers and non-ZKP credentials: verifiers have been letting Alice use her mom’s credit card since long before ZKP-oriented credentials were a thing. Trust gaps are a characteristic of careless interactions, not ZKPs.
7. It gets limited utility exactly backward.
The article claims that ZKP-oriented credentials “must introduce mechanisms that limit their utility.”[Abstract] The word “must” is the problem here. It is true that some advanced features of ZKPs come with constraints, and we have frankly discussed them in point 4 and point 5. Constraints aren’t news; they’re an inherent characteristic of tradeoffs, typical of advanced features in any technology. Holders and verifiers don’t have to depend on these features; they can limit themselves to just the capabilities of non-ZKP-oriented credentials if they like. But if they do access the extra options for privacy and repudiability that ZKP-oriented credentials offer, the use cases addressable with ZKPs grow into a superset of those addressable without them:
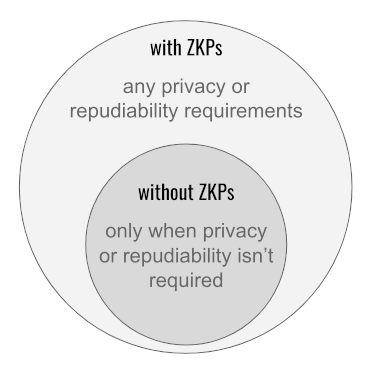
7.1 Various aspects of the “you can do more with ZKPs” assertion were proved elsewhere.
We saw in point 1 that by definition and intention, the boundaries of zero knowledge encompass all necessary facts. Using a far narrower and inaccurate definition, Arnold and Longley want us to believe that ZKP-oriented credentials are constrained by the purity of their zeroness to withhold vital facts from the verifier. But once the definition is corrected, this falls apart; zero knowledge proofs can match their non-zero-knowledge counterparts fact for fact. They just can’t leak anything superfluous.
Point 4 explains that ZKP-oriented credentials support all of the same mechanisms to bind a holder to a credential as their non-ZKP-oriented counterparts — plus some unique options that non-ZKP-oriented credentials lack. Note that these are options. Just because the tech that creates these options is active does not mean that verifiers must use the options as their basis of trust.
Point 5 clarifies that ZKP-oriented credentials support the same non-repudiation features as their non-ZKP-oriented counterparts. The extra option for negotiated repudiability with respect to the public is a value-add with ZKPs; it lets the verifier and the holder pick different tradeoffs together if they like, but it does not force trust to be achieved a particular way.
We saw in point 6 that the trust gaps imagined in the article are a result of foolish and unlikely behavior that could manifest regardless of which credential tech’s at play; it has no inherent relationship to ZKP features.
7.2 Specific examples are abundant.
Here are some specific examples of how ZKP-oriented credentials solve problems that their simpler counterparts cannot:
| Proof Requirements | Doable without ZKP? | Doable with ZKPs? |
|---|---|---|
| Use credentials to prove facts on a mortgage application, disclosing lots of Alice’s PII. | Yes | Yes |
| Prove Alice has an unexpired driver’s license so she can rent a car, disclosing lots of Alice’s PII. | Yes | Yes |
| Use a special-purpose “over-18” credential to prove only that Alice is over 18. | Yes (if better than article’s straw man) | Yes (same caveat) |
| Use a driver’s license or passport to prove only that Alice is over 18. | No | Yes |
| Prove to medical researcher that Alice is HIV positive — publicly non-repudiable (researcher CAN pre-prove it). | Yes | Yes |
| Prove to medical researcher that Alice is HIV positive — publicly repudiable (researcher CAN’T re-prove it). | No | Yes |
| Prove to Acme that a newly enrolled user is named Alice, and then prove it again later, without Acme being able to tell whether it’s the same Alice. | No | Yes |
| Prove to Acme’s HR dept only that Alice is a female employee in the Houston office, so she can make a semi-anonymous sexual harrassment complaint. | No | Yes |
| Prove only that Alice, identified strongly, has a credit score between 750 and 800, without revealing what the score is. | No | Yes |
| Prove only that Alice is female, over 45, lives in one of 10 postal codes, and has an annual income of six figures, without revealing further details. | No | Yes |
| Prove only that Alice possesses an unexpired major credit card, without revealing further details. | No | Yes |
| Prove only that Alice is a registered voter who hasn’t already voted in this election, without identifying her. | No | Yes |
| Prove only that credential A and credential B were issued to the same person, without revealing additional information. | No | Yes |
| Remotely prove that Alice is bound to a credential by a biometric, without disclosing the biometric to verifier. | No | Yes |
| Prove that Alice is bound to a credential by a link secret, where the secret is still protected by a bond that can be confiscated by anyone that knows it. | No | Yes |
8. It is wrong about ZKPs being especially vulnerable to advances in crypto.
An important claim in the article is that with ZKP-oriented credentials, “[g]reater trust must be placed in the shelf life of cryptography to prevent the user from being unwantonly correlated than alternative approaches.” [Abstract] The basis of this claim is elaborated in section 3.3, which incorrectly asserts:
ZKP ABC systems that encourage users to mix all of their identities and attributes together introduce a new risk: correlation across identities. Such systems use information hiding, or encryption, to enable a user to prove that their attributes are linked together. The user presents a value that has been mathematically modified by their correlation secret to the verifier. The expectation is that this operation cannot be reversed by the verifier. Each time they encrypt their correlation secret, they expose a different value, unless they are using link secret reuse to fill trust gaps. A user in this system is giving to every verifier an encrypted copy of the secret binding all of their identities together. This may be particularly surprising since the very party the user is trying to keep this information away from is the verifier. Fear that the verifier may correlate their information in undesirable ways is the whole reason for utilizing ZKPs. Since the encrypted secret is given directly to the verifier, user privacy is at the mercy of the security of the cryptographic scheme used. For example, if this cryptography is not quantum resistant, then a future quantum computer could decrypt this information. Revealing links across all of a user’s various identities and attributes catastrophically eliminates the user’s privacy.
The problem with this narrative is that it’s based on a false equivalence. Encryption is generally acknowledged to have a limited shelf-life due to advances in cryptanalysis and computing power. Because of this, it suits the authors’ purposes to have us to believe that link secrets are shared by encrypting them. If this were true, then link secrets might be vulnerable as Arnold and Longley claim.
But link secrets aren’t shared by encrypting them; in fact, they aren’t shared at all. Instead, they bind their owner using a technique called cryptographic commitments. Commitment schemes are the mathematical equivalent of a secure coin flip. They require Alice to make and share a commitment to a value V at an early time, and then later require her to prove characteristics of V. These mechanisms guarantee mathematically that she can’t change which V she chose; she’s bound to her earlier commitment, with no ability to manipulate the outcome. If she picked heads, she can’t claim she picked tails. If she is using link secret X, she can’t substitute link secret Y.[39]
Notice what’s shared in such a scheme: a commitment, not an encrypted secret. These are not at all the same thing. In point 4, we compared commitments to watermarks; the secret would be the printing equipment that makes the watermarks. You don’t embed printing equipment in currency; you embed hard-to-fake manifestations of printing equipment.
Both encryption and cryptographic commitments are forms of information hiding, and the article invites us to cross a mental bridge through that commonality: “…[s]uch systems use information hiding, or encryption.”[section 3.3] But the bridge is a mistake. Consider:
- Hiding my password on post-it notes in a desk drawer is a form of information hiding, but that doesn’t make it encryption.
- Deleting data on my hard drive is a form of information hiding, but that doesn’t make it encryption.
- Turning a gigabyte of my genome into a SHA-256 hash digest is a form of information hiding, but that doesn’t make it encryption.
Encryption has a complementary operation called decryption. This is what faster computers with better cracking algorithms might do. But cryptographic commitments have no such complement. They are nowhere near as reversible as encryption.
Cryptographic commitments are a bit like shadows. By inspecting a shadow, you can tell something about the object that cast it. You know the object existed, and you can estimate its visual magnitude at the point where it interrupted the light. You also know something about its shape. However, you cannot reconstruct a three-dimensional object from a two-dimensional shadow; an infinite number of three-dimensional objects could interrupt light in the same way. They could have any color or texture or mass or orientation or arrangement of opacities.
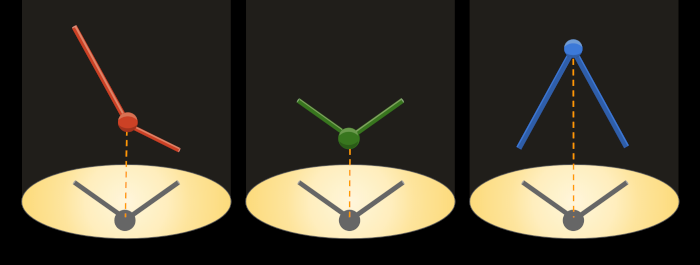
Similarly, the evidence of a cryptographic commitment that’s embedded in a ZKP credential can be used to prove to a verifier that the holder knows the secret — but it can’t be used to “decrypt” the link secret, because what’s there is only a one-way projection of the original value, not a complete, reversible transformation of it.
9. Its credential proxying scenario hides a real ZKP insight behind logic errors.
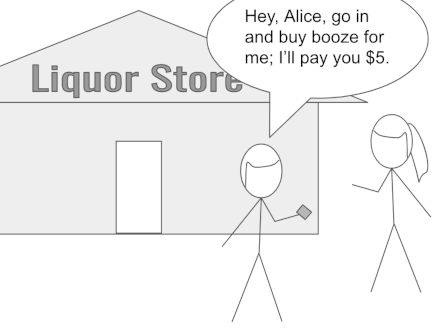
Example 2.6 in the article focuses on a scenario where malicious Alice offers to prove things on Bob’s behalf. The authors would have us imagine they’re describing an important proxying vulnerability inherent to ZKPs. “Unlike the non-ZKP case,” they claim, “the verifier cannot distinguish who is presenting the ZKP-derived credential or detect the proxy server.”[section 2.6]
But is this really true? If Arnold and Longley have revealed a vulnerability unique to ZKPs, how come Alice can proxy Bob with physical credentials?
And how come Alice can proxy Bob using non-ZKP-oriented credentials?
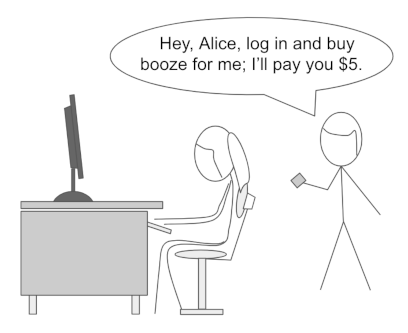
Faced with these examples, Arnold and Longley might quibble that in their variant, Bob does the presenting rather than Alice. But that’s perfectly possible with non-ZKP-oriented credentials, too. Here’s how it would work:
- Bob relays the verifier’s proof request to Alice.
- Alice generates a verifiable presentation by disclosing all fields of her driver’s license, adding the verifier’s requested nonce, and then signing the whole payload.
- Alice gives the verifiable presentation to Bob.
- Bob relays the presentation to the verifier.
- The verifier confirms that the presentation satisfies the “over 18” criterion, and that it’s been signed by a key properly authorized to create verifiable presentations for Alice’s DID. The verifier now knows that valid proof of “over 18” has been generated by Alice. This is true, in fact; the only problem is, Alice’s proof is granting privileges to Bob.
Various games could be played to try to close this gap, but none withstand careful analysis. This is a real vulnerability, as described. And notice that the verifier can’t detect the proxying. That’s because the inability to detect a proxy is a characteristic of proxies in general, not of ZKP proxies specifically. Although the mechanics of proxying vary slightly (physical credential display vs. simple digital signature vs. complex ZKP), the result is undetectable no matter which style of credential Alice uses.
Arnold and Longley claim that linkability closes this gap because it raises the specter of legal repercussions. The behavior of many college roommates who buy alcohol for one another argues against them. But maybe they claim a deterrent effect only for bulk fraud (Alice will attract attention if she buys hundreds of liters of alcohol per day, for weeks on end)? If so, and if simple linkability satisfies the verifier, then fine — linkability through identifier disclosure can be achieved with ZKP-oriented credentials just as easily as with the other credential style (see point 1.3 and point 2).
A somewhat stronger guarantee may be achievable with biometrics. As described in point 4.1, this is also straightforward with ZKP-oriented credentials. Some remote biometrics technologies include sophisticated liveness tests such that Alice would have to physically cooperate with the biometric scan, not just run a web service, to pull off the proxying. Is that level of assurance enough? It’s still not perfect…
The deeper truth here is that fraud and deterrent measures must be matched to whatever level of assurance a verifier requires. There is no binary standard that’s always right, and that’s magically addressed by one credential technology and not another. But there is one credential technology that gives a broader array of options than the other:
| Scenario | Appropriate Level of Assurance | Doable with non-ZKP creds? | Doable with ZKP creds? |
|---|---|---|---|
| Buying alcohol in person | Buyer matches biometric (proxy buying is still easy, but bulk buying is hard) | Yes | Yes |
| Buying alcohol remotely | Buyer matches remote biometric with liveness + disclosed identifier (proxy buying is easy, bulk buying discouraged by disclosure) | Yes | Yes |
| Buying movie tickets with senior discount | Just prove over 65 (no regulatory pressure for higher level of assurance; theater takes buyer’s word because egregious abuse will be detected when young person shows up at theater) | No | Yes |
| Entering a concert with verifiable cred as ticket | Ticket can only be used once; we don’t care who uses it | Awkward (cred bound, can’t transfer; hassle to re-issue) | Yes |
The real insight to draw from Example 2.6 is that credentials without ZKP support are problematic. Anywhere high assurance is needed, either credential type can provide them. But anywhere flexibility is worth having, only ZKPs are viable.
Summary (where we agree and disagree)
| Claim in AL article | Reality | Comment |
|---|---|---|
| When a verifier agrees to accept less assurance about attributes of a holder, they are making a trust tradeoff. | True | All credentials offer choices about how much is proved. This caveat is relevant regardless of ZKP usage. |
| Strongly identified holders are more likely to be trusted in some contexts. | True | Besides the basic dynamics that make this true, misunderstandings about ZKP technology could constitute a self-fulfilling prophecy. |
| Absolute anonymity is not desirable in many contexts. A bank won’t give a mortage to a lender they can’t take to court. | True | Absolute anonymity is almost never possible, even if it were desirable. See point 2.1. |
| The feature set of ZKP-oriented credentials maps directly onto the concept of primitive zero-knowledge proofs of knowledge. | False | See point 1. |
| ZKP-oriented credentials aim for / enforce absolute anonymity of the holder. | False | No, they aim to improve privacy. Sometimes that means a selectable degree of anonymity (see point 1.3 and point 2); other times it means granular control over repudiation (see point 5). |
| A proof that discloses a person’s name, phone number, or DID cannot be zero knowledge. | False | See point 1.3. |
| A proof that discloses a person’s name with ZKP-oriented credentials amounts to the same thing as showing a credential with only the person’s name. | False | With ZKPs, the existence and validity of the issuer’s signature, rather than its value, gets disclosed. Sometimes this difference matters. See point 1.3. |
| A holder/prover must be vulnerable to a verifier before it is reasonable to trust them. | False | A verifier must know that the holder/prover is constrained enough by incentives, context, technical possibilities, history, reputation, and similar factors to match the desired level of assurance. Trust isn’t binary, and it’s not purely reputation-based. Likewise, a holder/prover must know something about verifier constraints to extend trust the other way (a need that Arnold and Longley entirely ignore). See point 3. |
| ZKP-oriented credentials force verifiers to trust link secrets or to reject the tech. | False | Link secrets are always available to use, but verifiers can choose to trust them or not, per preference and circumstances. See point 4 and point 6.2. |
| ZKP-oriented credentials can’t be bound reliably to their holder. | False | See point 4. |
| Biometrics aren’t relevant to ZKP-oriented credentials, since they are guaranteed to disclose strong correlators. | False | See point 4.1. |
| Holders/provers must interact in a non-repudiable way in all cases, to achieve trust. | False | This is a good default, but there are meaningful corner cases where a repudiable proof is important. See point 5. |
| Credentials and proofs can be conflated for the purposes of analyzing ZKP trust. | False | The tech is called “zero-knowledge proofs,” not “zero-knowledge credentials,” for a reason. See point 6. |
| A thought experiment about a 1-attribute ZKPOK derived from a 1-attribute credential yields deep insights about the limits of ZKP tech. | False | Such an example is misleading and unrealistic. See point 6. |
| ZKP-oriented credentials are only useful in corner cases. | False | The set of use cases addressable with ZKP-oriented credentials is a superset of the ones addressable without them. See point 7. |
| ZKP-oriented credentials contain an encrypted copy of a link secret, and presentations derived from them give an encrypted copy of that secret to verifiers. Therefore they are susceptible to decryption if cryptography advances. | False | This false claim arises from a misunderstanding of a technique called cryptographic commitments. See point 8. |
| ZKP-oriented credentials are inherently, uniquely susceptible to a proxy attack. | False | All credentials are susceptible to proxying in various ways. Countermeasures can raise the level of assurance for both credential types, to the same degree and in roughly the same way. ZKPs offer more options than the alternative. See point 9. |
| ZKP-oriented credentials encourage correlation. | False | Just the opposite. See point 4.3. |
Learning more
Verifiable credentials are a new and exciting technology, and there’s been a rush to implement. But consensus has yet to emerge about many issues raised by these credentials. One of the deepest points of disagreement centers on privacy — what it means from a legal, technical, and philosophical perspective, what tradeoffs it entails, and how to best achieve it. This is the larger context for the Arnold Longley article and its rebuttal.
Some collateral topics and resources include:
- Verifiable Credential Data Model: This is the only standard for VCs today, and it is far more modest in scope than many people assume. It describes how credentials must be modeled conceptually, but not what their format should be or how they should be issued or presented. As a result, there are three competing and non-standardized formats for credentials; all are compatible with the standard data model, but lack interoperability with one another. See also these results of conformance to a verifiable credential test suite (the “Credly”, “Evernym”, and “Sovrin” columns embody ZKP features).
- A Gentle Introduction to Verifiable Credentials: Explains the backstory of verifiable credentials as a technology, including goals, common features, and important issues.
- Categorizing Verifiable Credentials: One of the struggles in both the Arnold Longley article and in this rebuttal is that we don’t have a broadly accepted mental model for how to categorize them. Arnold and Longley use “ZKP-oriented credentials” for one grouping, and I’ve kept that convention. They also use the word “traditional” to categorize some approaches; I think this adjective is dubious at best, given the immaturity of the field. There are lots of ways to understand how the landscape divides up. This blog post explores that issue in detail.
- The Dangerous Half-Truth of “We’ll be Correlated Anyway”: Explains why non-correlating credentials are still very important, despite the information that is already known, and will inevitably be known, about us.
- Alice Attempts to Abuse Her Verifiable Credential: A collaborative paper from the August 2019 Rebooting Web of Trust conference, from verifiable credential implementers in multiple organizations, spanning both ZKP- and non-ZKP-oriented technologies. Explores a malicious holder in far more detail than either the Arnold Longley article or this rebuttal does. Includes a discussion about vulnerabilities for all credential types.
- Verifiable Credential Threat Model (Aries RFC 0207): Provides a framework for discovering and categorizing many threat vectors, including a malicious holder, but also malicious verifiers, malicious issuers, and malicious third parties. The vulnerability that’s central to the Arnold Longley article, around malicious holder and transfer, is one of thousands of permutations this threat model imagines.
- What if I lose my phone?: Explores how ZKP credentials offer protections from abuse when a phone belonging to a legitimate holder is stolen. Introduces another protective mechanism for link secrets that this rebuttal didn’t even mention: agent authorization policy.
Endnotes
[1] Many amateur and journeyman discussions of ZKPs online offer a basic description similar to Arnold and Longley’s. This may be because the authors are either unaware of the distinction, or the distinction doesn’t matter in their context. The Wikipedia article on ZKPs (retrieved Jan 16, 2020) is inconsistent. In its Definition section, Wikipedia gives a correct, general ZKP formulation: “if the statement is true, no verifier learns anything other than the fact that the statement is true.” And in the introduction, it also notes correctly: “A zero-knowledge proof of knowledge is a special case when the statement consists only of the fact that the prover possesses the secret information.” However, earlier text in the introduction focuses on mathematically defined cryptographic proofs, and invites the ZKP=ZKPOK conflation by not clarifying the different levels of formality: “In cryptography, a zero-knowledge proof or zero-knowledge protocol is a method by which one party (the prover) can prove to another party (the verifier) that they know a value x, without conveying any information apart from the fact that they know the value x.”
[1] Expert cryptographers are careful about this distinction. Most ZKPs in their discipline have a rigorous computer science definition that involves mathematical notation, Turing Machines, simulators, systems of messages, and polynomial time. See these lecture notes from a Cornell CS class for a short version, or Lindell, Y. “How To Simulate It – A Tutorial on the Simulation Proof Technique” (chapter 6 in 2017’s Tutorials on the Foundations of Cryptography, https://doi.org/10.1007/978-3-319-57048-8_6 for an in-depth exploration. To see experts making the same distinctions between general ZKPs and narrow ZKPOKs that I’m claiming here, see, for example, a paper from the Security Protocols XVII conference, notes from a University of Maryland graduate cryptography course, the Zcash intro to zkSNARKs, these docs from SCAPI (a secure computation library), or an academic paper on ZKPOKs.
[1] For a better primer on ZKPs than Wikipedia, try this one from towardsdatascience.com. Notice that the “Where’s Waldo” illustration it offers involves disclosure (showing Waldo’s picture), not just proof of knowledge.
[2] Simari, G. “A Primer on Zero Knowledge Protocols.” 2002. http://j.mp/37RNSbj. Note that this primer from a reputable scholar, now eighteen years old, specifically discusses impersonation risks with ZKPs and how to combat them. It is an example of the discourse that’s already covered Arnold and Longley’s concerns in more formal circles. More examples appear throughout Yu, Z., Au, M.H., and Yang, R. “Accountable Anonymous Credentials.” in Advances in Cyber Security: Principles, Techniques, and Applications, 2019. https://doi.org/10.1007/978-981-13-1483-4_3. Note especially their detailed references.
[3] Goldreich, O. “A Short Tutorial of Zero-Knowledge.” Weizmann Institute of Science. 2010. http://j.mp/2HyTmNr.
[4] Goldwasser, S., Micali, S., and Rackoff, C., “The knowledge complexity of interactive proof-systems, SIAM Journal on Computing, 18(1), 1989, pp. 186-208. https://doi.org/10.1137/0218012. Note that this paper existed in some form as early as 1982. There’s a 1985 version, published for the IEEE Foundations of Computer Science conference that defines the adjective “0-knowledge” — but it is the 1989 version that gives the simple formulation above and that is most available today.
[5] “zkSNARKs in a Nutshell”. Ethereum Foundation Blog. Dec 2016. https://blog.ethereum.org/2016/12/05/zksnarks-in-a-nutshell/.
[6] Yehuda Lindell comments on this very distinction on StackOverflow, noting that cryptographers aren’t certain whether some types of ZKPs can be reduced to pure proofs of knowledge: https://crypto.stackexchange.com/q/37056.
[7] Singer, A. “The 3 Cybersecurity Rules of Trust.” Dark Reading. May 2019. http://j.mp/2SUH9Ie.
[8] Rouse, M. “What is principle of least privilege.” Advances in access governance strategy and technology. SearchSecurity. http://j.mp/2V58H0m.
[9] Rose, S., Borchert, O., Mitchell, S., and Connelly, S. “NIST 800-207: Zero Trust Architecture.” NIST. 2020. https://nvlpubs.nist.gov/nistpubs/SpecialPublications/NIST.SP.800-207-draft2.pdf. Olejnik, L. and Novak, J. “Self-Review Questionnaire: Security and Privacy.” W3C Editor’s Draft. Jun 2019. https://w3ctag.github.io/security-questionnaire/.
[10] See points 3 and 4 in “Core Fallacies”, Stanford Encyclopedia of Philosophy, http://j.mp/2TAy4GC.
[11] Camenisch, et al. “Specification of the Identity Mixer Cryptographic Library.” Section 2, p. 5. IBM Research. 2010. http://j.mp/2V3AGxa.
[12] See, for example, Blazy, O., Derler, D., Slamanig, D., and Spreitzer, R. “Non-Interactive Plaintext (In-)Equality Proofs and Group Signatures with Verifiable Controllable Linkability”. Topics in Cryptology – CT-RSA, 2016. https://eprint.iacr.org/2016/082.pdf. Related implementation in Hyperledger Ursa at http://j.mp/374Lrmb.
[13] See, for example, Gosh, E., Ohrimenko, O., and Tamassia, R. “Verifiable Member and Order Queries on a List in Zero-Knowledge”. Brown University, 2014. https://arxiv.org/abs/1408.3843. Implementation of a similar concept in Hyperledger Ursa at http://j.mp/2Rqeb2g.
[14] Lesavre, L., et al., “A Taxonomic Approach to Understanding Emerging Blockchain Identity Management Systems.” NIST. 2020. https://doi.org/10.6028/NIST.CSWP.01142020. For examples of scholarly research, see Benarroch, D., Campanelli, M., Fiore, D., and Kolonelos, D. “Zero-Knowledge Proofs for Set Membership: Efficient, Succinct, Modular”. International Association for Cryptologic Research. Oct 2019. https://eprint.iacr.org/2019/1255.pdf. Also Camenisch, J., Chaabouni, R., and Shelat, A. “Efficient Protocols for Set Membership and Range Proofs.” AsiaCrypt, 2008. https://doi.org/10.1007/978-3-540-89255-7_15. Implementation in Hyperledger Ursa at http://j.mp/370plBc and http://j.mp/360S9In.
[15] ZCash uses zkSNARKs to disclose some details of a transaction while hiding others. Disclosing values, including pseudonyms, has been a feature of Sovrin-style ZKP-oriented credentials since they were first released (personal knowledge). An implementation of ZKP disclosure exists in Hyperledger Ursa at http://j.mp/2NDvyeH.
[16] Garman, C., Green, M., and Miers, I. “Decentralized Anonymous Credentials.” 2013. https://eprint.iacr.org/2013/622.pdf.
[17] Identity Mixer specification. See endnote 11.
[18] Glenn, A., Goldberg, I., Légaré, F., and Stiglic, A. “A Description of Protocols for Private Credentials.” 2001. https://eprint.iacr.org/2001/082.pdf.
[19] Bichsel P., et al. D2.2 – Architecture for Attribute-based Credential Technologies – Final Version, Goethe University, IBM Research, and Microsoft NV, 2014. http://j.mp/30th3zq.
[20] “Digital Identity: Restoring Trust in a Digital World.” Mastercard. 2019. http://j.mp/2P51euh.
[21] ABC4Trust architecture; see endnote 19.
[22] For an example of how important these factors can be in guarantees of ZKP-based anonymity, see Kappos, G., Yousaf, H., Maller, M., and Meiklejohn, S. “An Empirical Analysis of Anonymity in Zcash.” USENIX Security Symposium 27. 2018. http://j.mp/2SCEgwM.
[23] Sweeney, L. “Simple Demographics Often Identify People Uniquely.” Data Privacy Working Paper 3, Carnegie Mellon University. 2000. http://j.mp/2SX8UQd.
[24] Eckersley, P. “A Primer on Information Theory and Privacy.” Electronic Frontier Foundation. 2010. http://j.mp/2Hztyk6.
[25] Rocher, L., Hendrickx, J, and de Montjoye, Y. “Estimating the success of re-identifications in incomplete datasets using generative models.” Nature Communications, volume 10, article 3069. Jul 2019. https://www.nature.com/articles/s41467-019-10933-3.
[26] See this discussion about the law on wecard.org: http://bit.ly/2KcuUCq.
[27] “Public Health Implications of Raising the Minimum Age of Legal Access to Tobacco Products.” National Academies Press. 2015. https://www.nap.edu/read/18997/chapter/8.
[28] See Sovrin Foundation, “What If I Lose My Phone?”, 2019, http://j.mp/2SYSKpJ.
[29] The watermarks derived from a master image typically resemble the originally very strongly, because they are meant to be checked for likeness by an untrained human eye. On the other hand, the cryptographic commitments derived from a link secret and embedded in credentials use a one-way transformation such that they can’t be reversed, either in the credential or in later proofs that knowledge of the link secret. This is a major aspect of ZKP cryptography that Arnold and Longley get wrong. See point 8.
[30] Notice that watermarks are not the same as the printing equipment that produces watermarks. This is another subtlety that escapes Arnold and Longley, who have the mistaken idea that link secrets are encrypted in credentials and proofs. See point 8.
[31] See Dingle, P. et al. “Alice Attempts to Abuse a Verifiable Credential.” Rebooting Web of Trust 9. Aug 2019. http://j.mp/2SQtbag. Also Hardman, D. and Harchandani, L. “Preventing Transferrability with ZKP-based Credentials.” Rebooting Web of Trust 9. Aug 2019. http://j.mp/2nzqldZ.
[32] See 9.2, Policy Registries, in DKMS Architecture v4 (research funded by US Department of Homeland Security and currently embodied in Hyperledger Aries RFC 0051: http://j.mp/2V6j6bV. Also, Sovrin Foundation, “What If I Lose My Phone?”, 2019, http://j.mp/2SYSKpJ.
[33] “Electronic Identity Credential Trust Elevation Framework Version 1.0.” OASIS. 2014. http://j.mp/2wLGEbU.
[34] Hardman, D., Harchandani, L., Othman, A., and Callahan, J. “Using Biometrics to Fight Credential Fraud.” IEEE Communications Standards. Dec 2019. https://doi.org/10.1109/MCOMSTD.001.1900033.
[35] See Smith, S. “Zero Trust Computing with DIDs and DADs.” Rebooting Web of Trust 7. Aug 2018. http://j.mp/3286tP9. Also Buechner, J. and Tavani, H. “Trust and multi-agent systems: applying the ‘diffuse, default model’ of trust to experiments involving artificial agents.” Ethics and information Technology. 2011. https://doi.org/10.1007/s10676-010-9249-z. Also Sayler, A. “Securing Secrets and Managing Trust in Modern Computing Applications.” University of Colorado. 2016. http://j.mp/2vNQSba. Also the discussion of sybil attacks in Hammi, M., Hammi, B., Bellot, P., and Serhrouchni, A. “Bubbles of Trust: a decentralized Blockchain-based authentication system for IoT.” Computers & Security. 2018. http://oadoi.org/10.1016/j.cose.2018.06.004. Also Werbach, K. The Blockchain and the New Architecture of Trust, p. 98. MIT Press. 2018.
[36] See Camenisch, J. and Shoup, V. “Practical Verifiable Encryption and Decryption of Discrete Logarithms.” Advances in Cryptology – CRYPTO 2003. https://doi.org/10.1007/978-3-540-45146-4_8. Also Lyubashevsky, V. and Neven, G. “One-Shot Verifiable Encryption from Lattices.” EUROCRYPT 2017. https://eprint.iacr.org/2017/122.pdf. See also the article cited in endnote 36.
[37] Camenisch, J. and Lysyanskaya, A. “An Efficient System for Non-transferable Anonymous Credentials with Optional Anonymity Revocation.” International Conference on the Theory and Applications of Cryptographic Techniques. 2001. https://doi.org/10.1007/3-540-44987-6_7.
[38] See Camenisch, J., et al. “How to win the clonewars: efficient periodic n-times anonymous authentication.” CCS ’06: Proceedings of the 13th ACM conference on Computer and communications security. Oct 2006. https://doi.org/10.1145/1180405.1180431. For a less formal summary, see Technique 2 in Hardman, D. and Harchandani, L. “Preventing Transferrability with ZKP-based Credentials.” Rebooting Web of Trust 9. Aug 2019. http://j.mp/38Gs2bR.
[39] Damgård, I. and Nielsen, J. “Commitment Schemes and Zero-Knowledge Protocols.” Aarhus University, BRICS. 2011. http://j.mp/2P6BAoQ.